Comment la data science peut aider à l’implantation des commerces ?
À l’occasion de notre participation au concours Data City Paris, organisé par Numa, nous avons pu réfléchir aux problématiques associées au challenge : « dynamiser les commerces locaux». Ou comme nous l’avions compris, comment fournir à partir de données, une assistance aux choix de lieu d’implantation. C’est là tout l’intérêt du géodécisionnel : croiser des données géographiques pour visualiser un résultat, une véritable aide à la décision pour dynamiser ces implantations. N’ayant pas de données « à nous », nous avons cherché à rassembler celles disponibles qui nous semblaient pertinentes. Une des premières problématiques identifiée est la disparité des formats de jeux de données que nous souhaitions prendre en compte.
Pour illustrer notre réflexion, plaçons-nous dans le cas particulier où l’on cherche à trouver un lieu d’implantation dans le 19ème arrondissement pour un commerce, et faisons trois hypothèses (un peu simplistes mais ce n’est pas l’objet ici 🙂 ):
- il est préférable de ne pas trop avoir de concurrence à proximité,
- être proche des transports en commun est un avantage,
- plus la densité de population est forte, mieux c’est.
Dans ce cas relativement simple, prenons pour exemple trois jeux de données facilement récupérables en lien avec nos hypothèses:
- les commerces parisiens classés par type (opendata.Paris.fr),
- les données socio-démographiques : population et superficie par IRIS,
- les données de transport : ligne de transport en commun (données OSM)
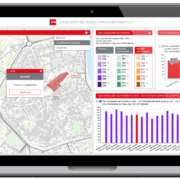
Il est assez facile de visualiser ces trois jeux de données séparément, comme on peut le voir sur les images ci dessous :
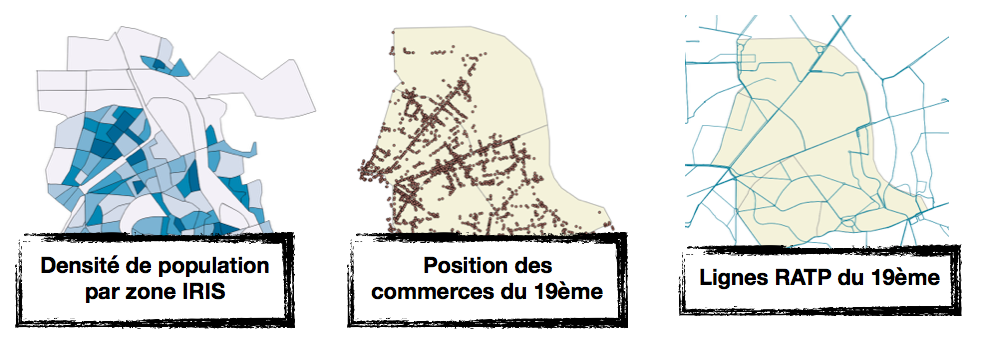
Cependant, avec les trois sources de données séparées, il est difficile de percevoir une information qui pourrait être utile. On pourrait penser les superposer, mais sous ces formats disparates cela ne permettrait pas forcément d’améliorer la lisibilité. L’idée qui nous est venue à l’esprit était de choisir un format géographique intermédiaire. Pour ce cas nous avons choisi de découper le territoire en hexagones. Ensuite, pour chacune des trois sources de données d’intérêts, nous l’avons transposée au sein de ce format intermédiaire, ainsi, chaque hexagone possède trois indicateurs :
- un score de densité, représenté ci-dessous de blanc (faible densité) à bleu foncé (forte densité),
- un nombre de commerces, représenté de beige (très faible) à marron (nombre élevé),
- un indicateur de présence de transports en commun, représenté en vert si positif.

Il est ensuite plus aisé d’avoir une représentation visuelle cohérente de ces ensembles de données.
Il suffit de « superposer » les trois sources de données transformées, c’est a dire de calculer un score d’attractivité à partir des trois indicateurs.
Ensuite, on peut rapidement percevoir une indication sur les zones pertinentes pour l’installation d’un nouveau commerce (relativement à nos hypothèses) : plus une zone tend vers le vert, plus elle est attractive.

Cette méthode, en plus de permettre une visualisation uniforme des différents jeux de données, facilite aussi par la suite l’application d’outils de data science avancés, qui permettent une assistance à la prise de décisions… mais ça, ce sera le sujet d’un prochain article !
Article rédigé par Gautier Daras.